

Stability AI 偷偷发布黑科技,秒杀Suno AI 的音乐生成!
AI 圈又有大新闻啦!Stability AI 又悄悄放出一个大招,这次不再是画图,而是音乐生成!而且还是开源的!
这个新工具叫 Stable Audio Open,简单来说,用文字就能生成各种音频——无论是鼓点、旋律,还是环境音效,全都不在话下!最最最重要的是,它还能为 Sora 和可灵 这些视频生成配音!接下来我介绍3种使用方法
1.最简单在线使用
Stable Audio 2.0
【点击前往】
2.本地一键安装包:【点击下载】,适合新手,低配的电脑也能运行,但是效果没有第3种好!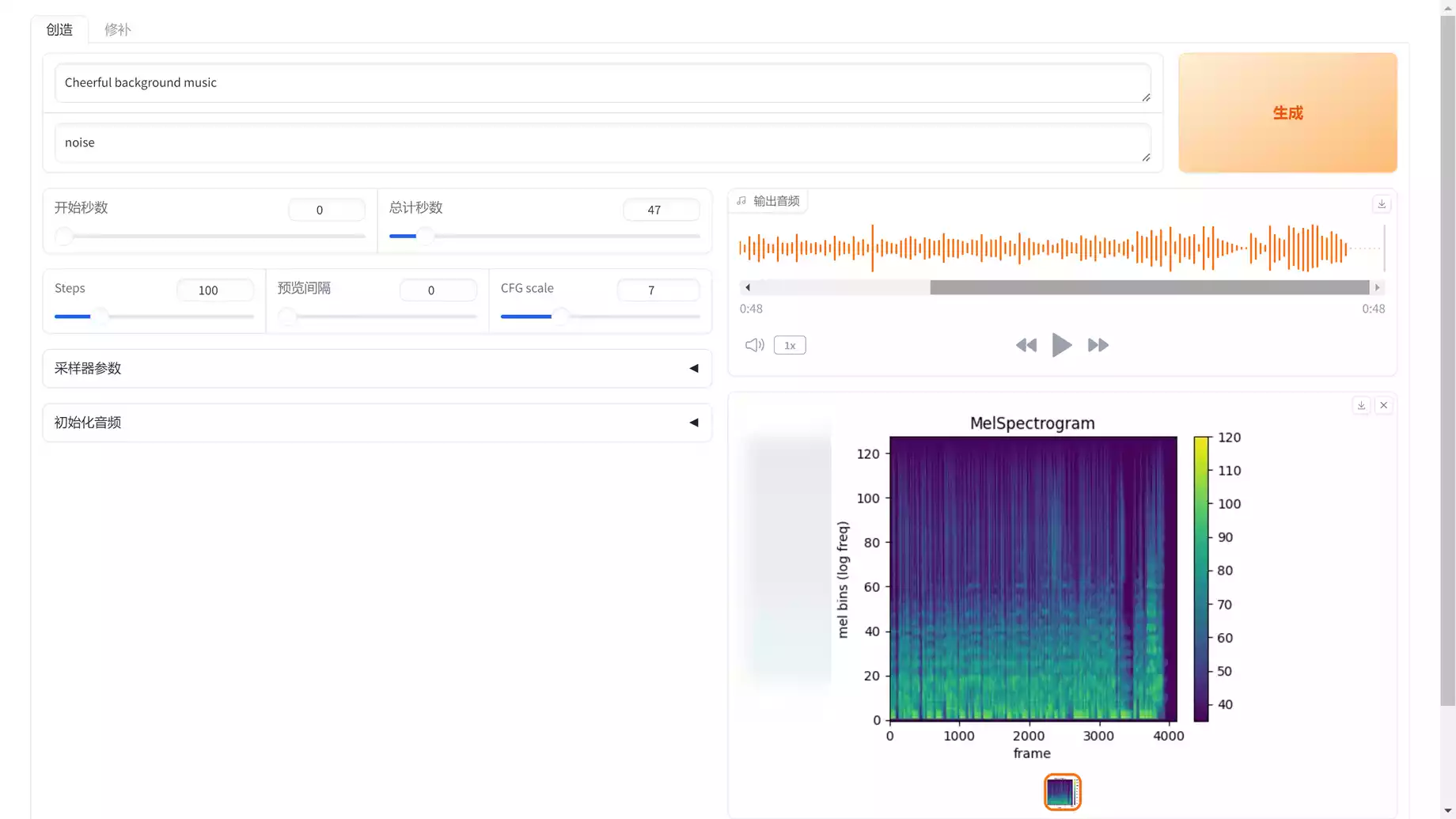
3.手动安装
首先,将存储库克隆到本地机器:
创建虚拟环境
Windows :
macOS 和 Linux:
安装所需的软件包
安装稳定的音频工具和必要的软件包setup.py:
Windows 用户的额外步骤
为了确保 Gradio 使用 GPU/CUDA 而不是默认使用 CPU,请卸载并重新安装torch、,torchvision并torchaudio使用正确的 CUDA 版本:
配置
config.json根目录中包含一个示例。对其进行自定义以指定自定义模型和输出的目录(.wav 和 .mid 文件将存储在此处):
使用方法
 运行 Gradio 界面
运行 Gradio 界面
使用批处理文件或直接从命令行启动 Gradio 界面:
批处理文件示例:
或命令行:
 生成音频和 MIDI
生成音频和 MIDI
Gradio 界面中的输入提示会生成音频和 MIDI 文件,这些文件将按照 中指定的方式保存config.json。
该界面已经扩展了 Bar/BPM 设置(可修改用户提示 + 样本长度条件)、MIDI 显示 + 转换,还具有动态模型加载功能。
模型必须与附带的配置文件一起存储在其自己的子文件夹中。即,一次微调可以有多个检查点。所有相关检查点都可以放在同一个“model1”子文件夹中,但重要的是,它们的相关配置文件包含在与检查点本身相同的文件夹中。
要切换模型,只需使用下拉菜单选择要加载的模型,然后选择“加载模型”。













